
Side note: Some aspects are simplified. The purpose of this article is not to teach how Neural Networks work in detail, but give a general overview for the public.
Ever since the emergence of computation, there was an aspiration to simulate and reproduce biological processes. The question was not whether it would be possible to make smart machines, but how and when. The term artificial intelligence is a very broad term which covers many fields. For vision, however, one particular field is interest: Neural Networks.
Regular Neural Networks aim to simulate the way a brain works: a neuron fires depending on how many of its connections before it have fired. The basic concept used, was to split the artificial neurons into groups, or layers. Each neuron in a single layer is connected to each neuron in the layer before it, and fires itself if enough of its connections have fired. The threshold for each neuron to fire, is different for each one, which eventually causes the neurons in the last layer to fire differently on different inputs.
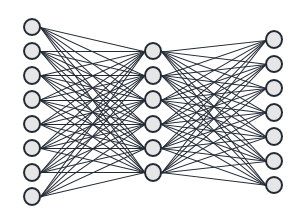
The way to find the proper thresholds (or weights) for each neuron would be a long and tedious process, which depended on the intended use. The final network would eventually contain many blank connections, reflecting the fact that neurons in a brain have specific functionalities, and groups of neurons work together. The more neurons a network had, the longer it takes to find the final configuration. So although this concept opened significant capabilities, due to the low computational power available, and vast size needed for practical use, the technology could not (yet) be applied widely adopted for vision purposes.
When research showed that certain neurons in brains of cats and monkeys reacted specifically to a certain part of the visual field, it became clear that for a Neural Network to actually work well, we not only needed more computational power, but also specialised “neurons” within these networks. The aim was not to lose spatial information, which was the case in regular Neural Networks, and make sure groups of neurons can actually perceive patterns in a more efficient way, without leaving that aspect up to chance during the configuration phase.
These highly specialised layers, called Convolutional Layers, will be discussed in Part 2 of this series. Stay tuned for more!