
Side note: Some aspects are simplified. The purpose of this article is not to teach how Neural Networks work in detail, but give a general overview for the public.
In Part 1 of this series, we discussed the basics of Neural Networks and the way they simulate biological neurons. In this part, we are going to dive into specialized neural layers called convolutions.
Shortly stated, a convolutional layer is a specialized layer that takes into account spatial distribution, as our own brain seems to do as well. It does so by “convolving” its input (image) using a predefined shape called a kernel, in this example a 3×3 square, which scans over its entire input. The kernel acts like a sort of filter, and only lets through certain features of the original image such as a specific colour, or only the edges of objects. A single convolutional layer consists of a multitude of such filters, that each produce a new “point of view”. The subsequent convolutional layer can then use these new features as an input to extract new combined features, for example edges of green objects, etc. The features get more and more abstract, but the notion of what it represents becomes clearer. For example, if the image contains an edge of a green object on the left and right of the picture, and mostly green in the middle, it could be a plant.
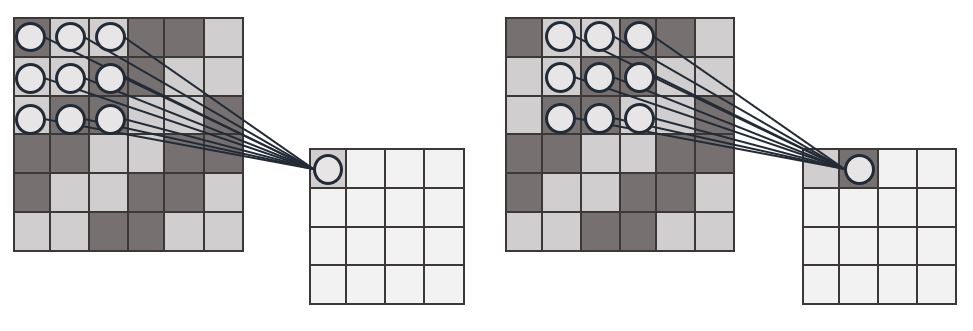
This design is especially convenient due to not needing as many neurons as its input to be able to process it. Kernels are small, and the processing thereof is relatively easy. Coincidentally, kernels take into account spatial relations by always looking at neighbouring pixels in the first place.
Finally, after several convolutional layers, the image is reduced to a list of features, which can then be fed to a regular neural network to categorise it. The totality of the neural network consisting of convolutional layers and the final categorical layers, is called a Convolutional Neural Network, or CNN. When properly designed, these networks can categorize many images and “recognize” faces, objects, or other features.
Now we have briefly introduced the notion of CNN’s, we have only talked about the neurons as a fixed set of weights or thresholds. In the Part 3 of this series, we will discuss Machine Learning and the way it can be used to set the correct weights.